Hay varios algoritmos clave que debes conocer si quieres entrar en el mundo del machine learning y data science.
Te los explicamos en este video:
Si quieres puedes seguir leyendo.
En este artículo hablaremos de los algoritmos que se suelen aprender cuando empiezas a aprender sobre machine learning y ciencia de datos y que debes conocer.
Regresión Lineal
El primer algoritmo que vamos a mencionar es la Regresión Lineal. Es el primero que se suele aprender cuando empiezas a aprender estadística y Machine Learning.
¿Cómo funciona la regresión lineal?
- Se crea una línea para predecir valores
- Es muy fácil de visualizar
- Puedes dibujar una línea para ver cómo se predice el resultado
A continuación, te mostramos un ejemplo:
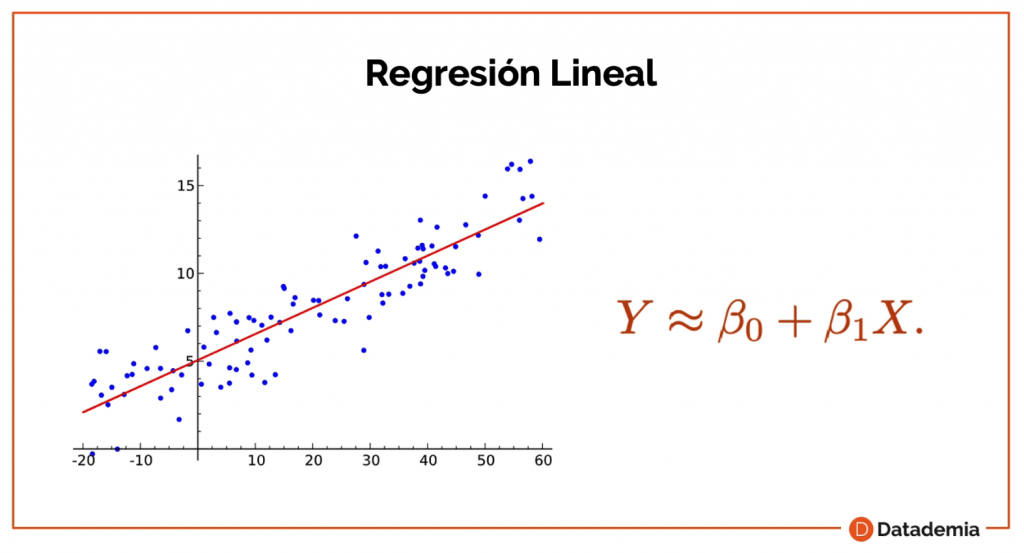
Como puedes ver, tenemos un montón de datos y hemos creado una línea que predice estos datos.
La fórmula suele ser: Beta 0, que es donde cruza el eje Y, y Beta 1, que es la pendiente que tiene. Entonces, cuanto más alto es Beta 1, más pendiente tendría.
Luego, podemos utilizar la suma de los errores para ver el error medio que tiene nuestra regresión lineal en relación a nuestros datos.
Regresión Logística
La regresión logística es un modelo de regresión para estimar la probabilidad de un resultado binario, por ejemplo:
- Diagnosis de enfermedades
- Si el correo es spam o no
- Sí o no para la devolución de un préstamo a un banco
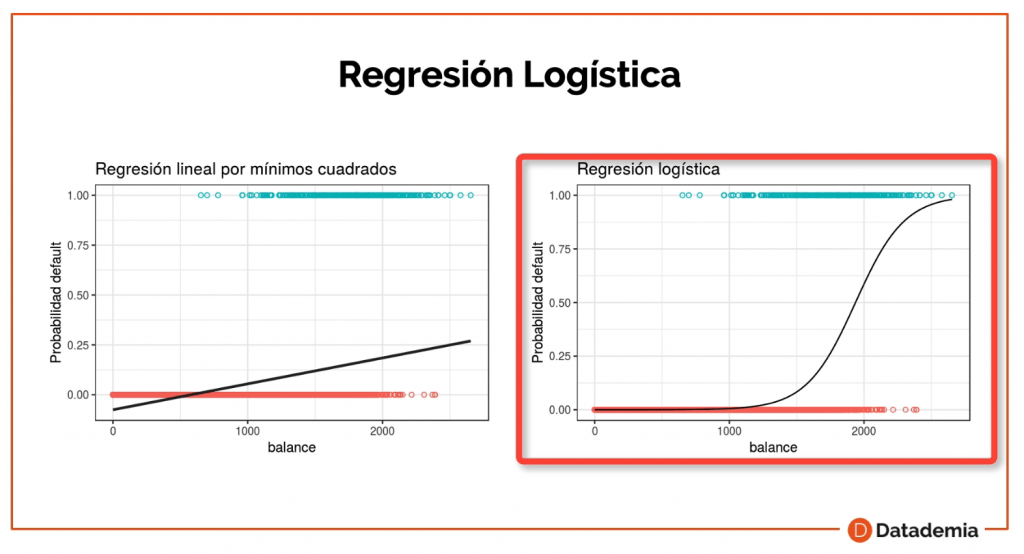
Básicamente, en estos problemas donde tenemos un resultado de 1 o 0 que es binario, no podemos crear una Regresión Lineal. Por lo tanto, tenemos que crear una Regresión Logística.
Esta Regresión Logística utiliza una función que nos permite calcular la probabilidad de que un resultado sea de 0 a 1. Por ejemplo, si nos sale un 0,75 tenemos una alta probabilidad que el resultado sea uno.
KNN – Vecinos Próximos
El siguiente algoritmo que debes conocer es KNN – Vecinos Próximos. Este es un algoritmo supervisado de clasificación que nos permite predecir la etiqueta de datos desconocidos utilizando el número K de vecinos próximos y hacer una votación.
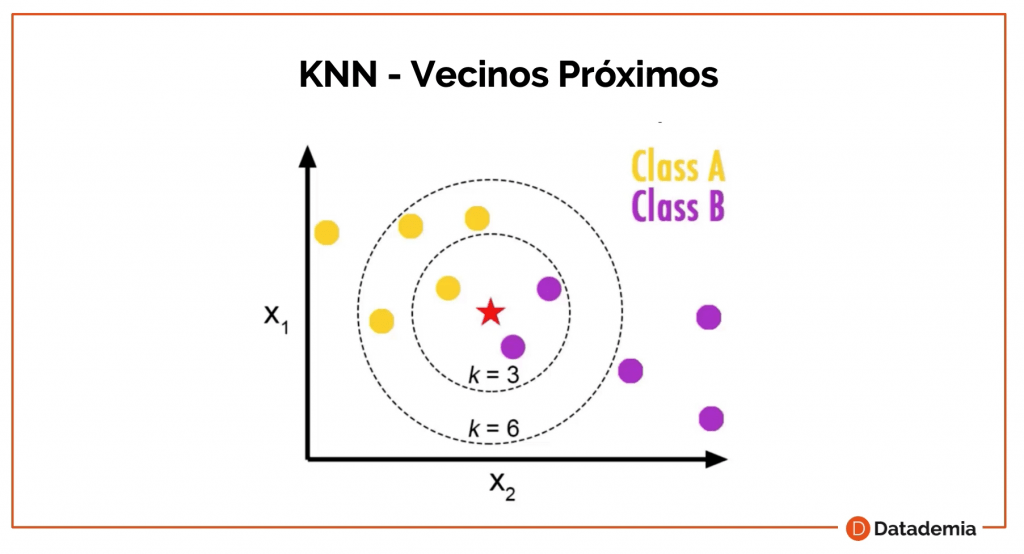
Como ves en este ejemplo, cuando introducimos un punto nuevo tendríamos que escoger un valor de K.
Este valor de K nos indica cuántos vecinos próximos podemos analizar. En este caso, K = 3 nos dice que tenemos tres vecinos próximos y dos de ellos son clase B, entonces este nuevo punto será considerado clase B.
Sin embargo, si utilizamos K = 6 vemos que de los 6, 4 son clase A, entonces, como tenemos más vecinos próximos, el punto nuevo sería considerado clase A.
Árboles de Decisión
El siguiente algoritmo son los Árboles de Decisión y los Bosques Aleatorios. Un Árbol de Decisión es un algoritmo supervisado donde se crea un mapa de los posibles resultados de una serie de decisiones.
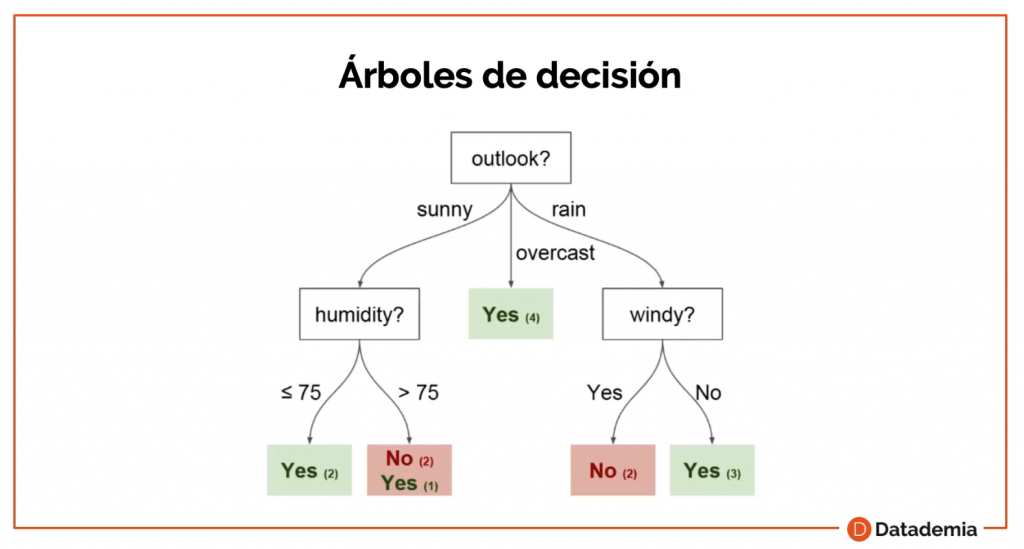
En el ejemplo, dependiendo de cada resultado, vamos bajando por el Árbol de Decisión y tomando decisiones.
¿Qué es un Bosque Aleatorio?
Un bosque aleatorio es básicamente un montón de arboles de decisión que se utiliza para conseguir un mejor rendimiento. Creamos muchos bosques de forma aleatoria y utilizamos el resultado final de todo esto agregado, para tener un mejor resultado.
Máquinas de Soporte Vectorial
El siguiente algoritmo que debes conocer son las Máquinas de Soporte Vectorial o SVM.
Son algoritmos de aprendizaje supervisado que analizan datos y reconocen patrones. Son utilizados para la clasificación y regresión.
Es una representación de puntos en espacio mapeados para cada categoría que está dividido con espacio más ancho posible, como lo podemos ver en el siguiente ejemplo.
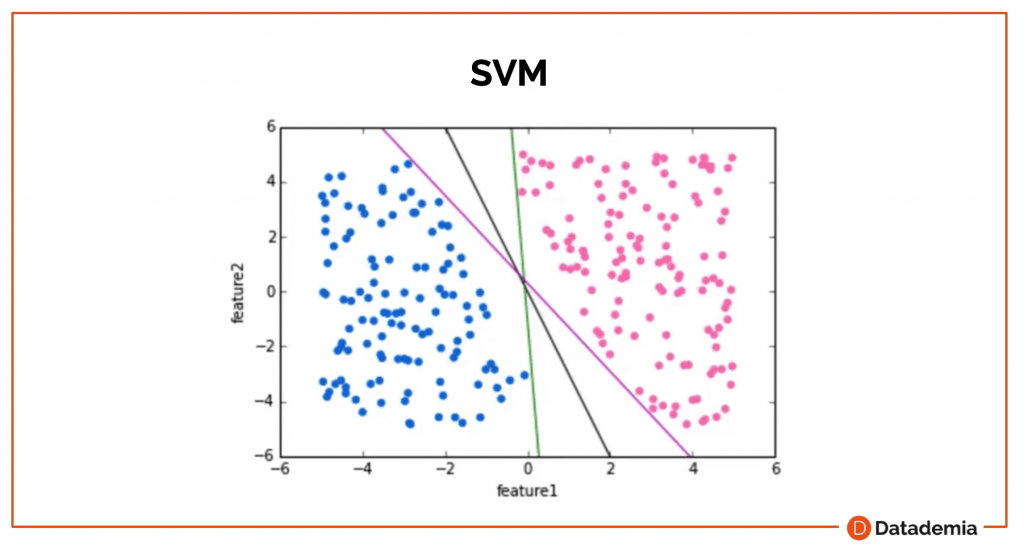
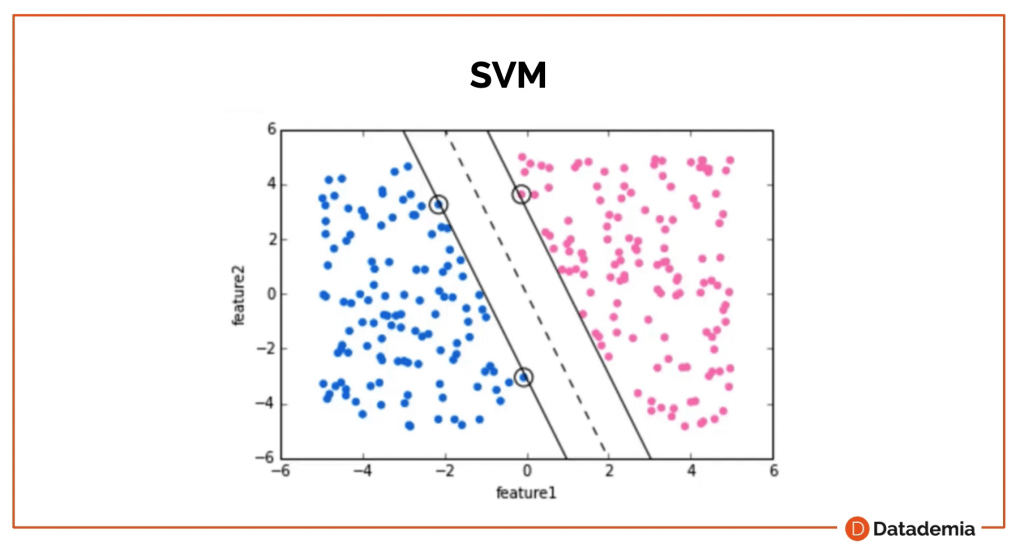
Si tenemos algunos datos con dos dimensiones, podríamos crear una línea o varias líneas, y al final elegimos el espacio más ancho posible entre las dos dimensiones. Estos puntos más extremos donde toca la línea del ancho, son los soportes vectoriales. De ahí viene el nombre del algoritmo.
K-Means Clustering
El siguiente algoritmo que debes conocer es el K-Means Clustering. Es un algoritmo de aprendizaje no supervisado para agrupar datos.
¿Qué problemas típicos de clustering existen?
- Agrupar documentos similares
- Agrupar clientes basados en características
- Segmentación de mercado
- Identificar grupos físicos similares
El objetivo es dividir los datos en grupos para que las observaciones dentro de cada grupo sean similares, como vemos en el siguiente ejemplo.

¿Cómo funciona el algoritmo de K-Means?
- Eliges un número de K
- Asignas aleatoriamente un punto a cada cluster
- Calculas el centro de cada cluster y asignas cada punto al cluster donde está más cerca el centro del cluster

No hay respuesta correcta. Puede haber diferentes grupos, diferentes números de grupos, y ninguna respuesta es realmente correcta.
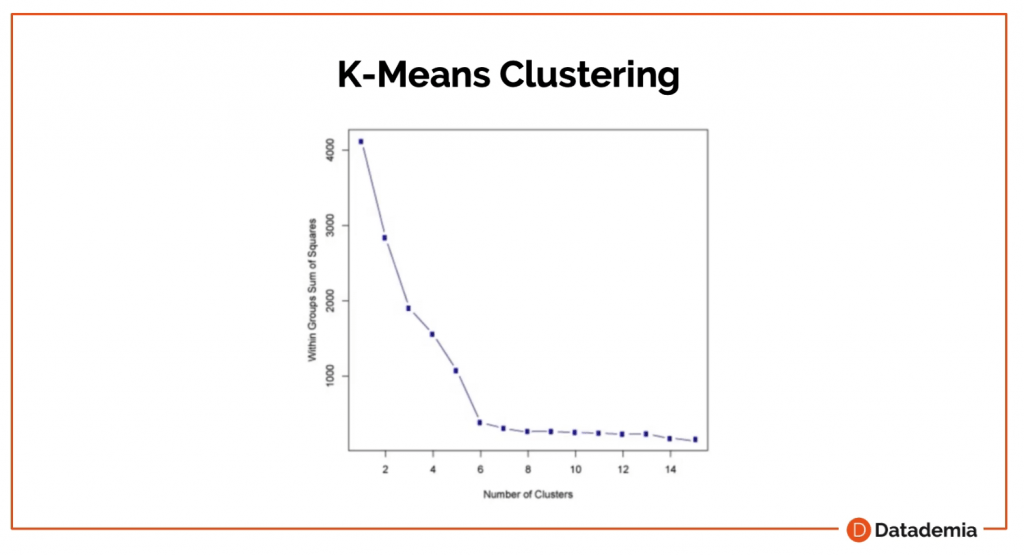
¿Cómo decidimos cuántos clusters escoger en K-Means?
Creamos un gráfico con la suma de los errores cuadrados que suele tener forma de codo. Como verás en el ejemplo, el cambio más drástico en el codo es donde está la punta del codo, en el 6. Entonces, utilizaríamos el 6, en este caso, para elegir el número de clusters
PCA
El siguiente y último algoritmo que debes conocer es PCA o Análisis de Componentes Principales.
Es un algoritmo de aprendizaje no supervisado para examinar las interrelaciones entre las variables.
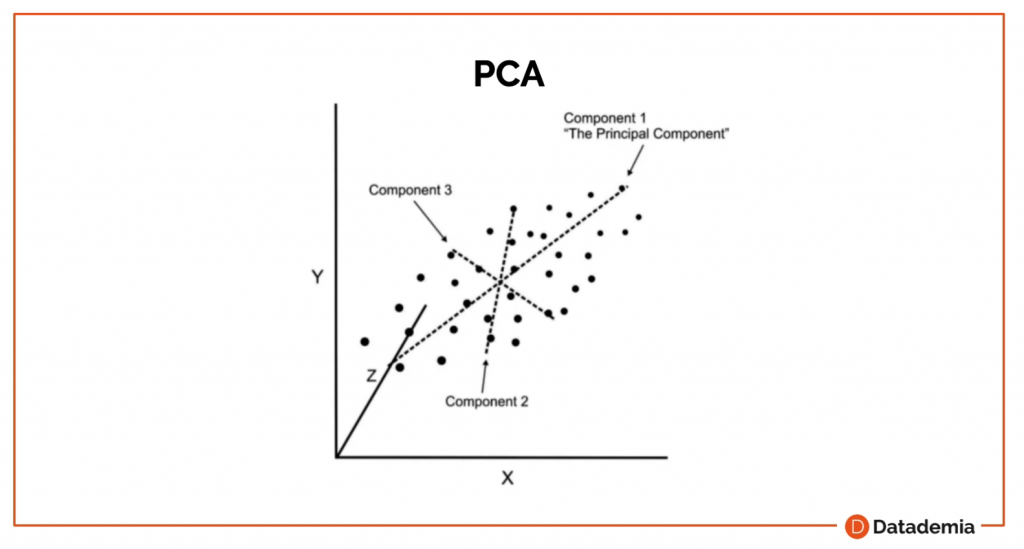
Como vemos en el ejemplo, tendríamos una línea de regresión, que lo acabamos de mencionar con anterioridad, pero también podríamos crear otra línea, otro componente, donde explicaríamos parte de la variación. Además, podremos añadir un tercer componente y así sucesivamente.
La idea es reducir los datos en un par de componentes principales que expliquen la mayoría de la variación. Esto lo podemos hacer antes de crear nuestro algoritmo de predicción.
¿Quieres aprender todo esto y más?
Si quieres aprender todo esto y convertirte en un científico de datos, en Datademia ofrecemos un bootcamp donde aprenderás todo lo necesario para entrar en este mundo de los datos donde las oportunidades laborales son enormes y están acompañados de grandes salarios.

¡Nos vemos en clase!
Fundador de Datademia y formador especializado en análisis de datos, ciencia de datos, ingeniería de datos y negocios.
Ayudo a profesionales a adquirir habilidades prácticas a través de formaciones online en Datademia para impulsar sus carreras. Conecta conmigo en LinkedIn.


