Machine Learning o aprendizaje automático es un ámbito de la inteligencia artificial donde una máquina es capaz de aprender por sí sola, usando datos del pasado.
En este video te lo explicamos:
Machine Learning está en todos lados, en las recomendaciones de Netflix o Amazon que tan bien adivinan lo siguiente que queremos ver o comprar, en las respuestas automáticas de Gmail cuando estamos escribiendo un correo o en las respuestas de voz de Alexa o Siri.
Tres tipos de Machine Learning
Hay tres tipos de algoritmos de machine learning (aprendizaje automático):
- Aprendizaje supervisado
- Aprendizaje no supervisado
- Aprendizaje por refuerzo
Hablemos brevemente de cada uno de ellos.
Aprendizaje Supervisado
El aprendizaje supervisado es el tipo de aprendizaje más común y más sencillo. Consiste en hacer una predicción basada en datos ya etiquetados. Por ejemplo, imagínate una base de datos de fotos de perros y gatos:


Usando muchas fotos ya etiquetadas un modelo debería poder distinguir y etiquetar nuevas fotos no etiquetadas que pasan por ese modelo.
Ejemplos:
Predicciones: Podríamos crear un modelo usando datos de otros gatos que nos dijese cuando el pulso de nuestro gato sea alto y así poder predecir cuándo deberíamos llevarlo al veterinario.
Predicciones con tiempo: Para predecir cuánta comida tenemos que comprar podríamos usar los datos de cuánta comida ha comido nuestro gato, utilizando datos de las estaciones del año y los incrementos durante cada año para saber cuánto comerá este año, este mes o esta semana.
Rotación de gatos (Churn en inglés): Le damos de comer cada día también a un gato de la calle y queremos saber si se irá o no. Gracias a los datos de antiguos gatos a los que dábamos de comer podemos predecir si este gato seguirá con nosotros o se irá.
Aprendizaje no supervisado
En este tipo de aprendizaje no tenemos etiquetas pero intentaremos usar una cierta estructura en los datos para poder interpretar si es un perro o un gato. Podemos crear clusters (grupos) y, como sabemos que solo tenemos fotos de gatos o perros, podemos dividir los datos en dos clusters, uno de perros (azul) y otro de gatos (rojo) y ver si los resultados encajan con la realidad.
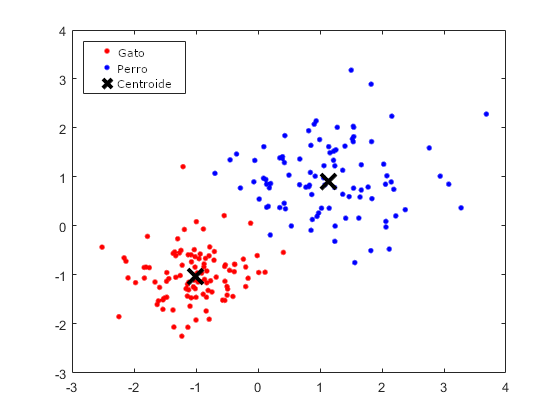
Como la mayoría de modelos, éste no es 100% preciso y puede ser que en algunos casos muy parecidos haya puesto la foto en el grupo incorrecto. Como ves en el gráfico superior hay puntos rojos y azules muy cerca uno de los otros indicando que las fotos son tan parecidas que al modelo le cuesta determinar si es un perro o un gato y en algunos casos se equivoca.
Ejemplos:
Fraude: Entre nuestros gatos, hay algunos que roban la comida del perro. Podríamos seguir el apetito de nuestros gatos para ver cuál de ellos ha comido más. La verdadera dificultad estará en diferenciar cuál de nuestros gatos tiene menos apetito, ya sea porque normalmente come menos o porque de verdad se ha comido la comida del perro.
Segmentación de Clientes: Queremos hacer un análisis de mercado para entender el comportamiento de nuestros gatos. Tenemos varios tipos de gatos diferentes pero les damos de comer de la misma forma. Queremos darles la mejor comida posible, por eso les separaremos en clusters para darles diferentes comidas a los diferentes tipos de gatos.
Aprendizaje por Refuerzo
Para la mayoría de empresas, normalmente, es suficiente usar los dos tipos de aprendizaje automático mencionados antes para llevar a cabo la mayoría de tareas. El aprendizaje por refuerzo funciona usando retroalimentación como respuesta a sus acciones. Después de muchas repeticiones aprende de sus errores. Por ejemplo es usado en robótica, drones o coches autónomos. También es utilizado en juegos o en anuncios online.
Imagínate que tienes un robot gato y quieres enseñarle a andar. Hay que intentar enseñarle a andar sin que se rompa. Si empieza a andar y se encuentra con unas escaleras, se caerá por las escaleras muchas veces antes de que consiga aprender a bajarlas. Por eso, al menos que tengas muchos robots disponibles, es mejor que aprendan al principio usando simulaciones.
¿Donde puedo aprender ML?
En Datademia puedes aprender sobre el machine learning en nuestro Data Scientist Bootcamp donde enseñamos machine learning y todo lo necesario para convertirte en un científico de datos. Aprenderás la básica de la programación para crear modelos de aprendizaje automático supervisados y no supervisados.

¿Quieres aprender más sobre lo que hace un científico de datos?
En este artículo hablamos de lo que hace un científico de datos y como convertirte en uno.
Fundador de Datademia y formador especializado en análisis de datos, ciencia de datos, ingeniería de datos y negocios.
Ayudo a profesionales a adquirir habilidades prácticas a través de formaciones online en Datademia para impulsar sus carreras. Conecta conmigo en LinkedIn.


