En este artículo vamos a enseñarte sobre lo que es, donde y como se utiliza un data pipeline.
Un Data Pipeline, o una canalización de datos en español, es un conjunto de procesos automatizados que permiten la transferencia de datos de una fuente a un destino específico.
Estos procesos pueden incluir la extracción de datos de diferentes fuentes, la transformación de los datos para hacerlos compatibles con el destino y la carga de los datos en el destino.
Los data pipelines son comúnmente utilizados para procesar grandes volúmenes de datos en sistemas de Big Data y en aplicaciones de inteligencia artificial y aprendizaje automático.
Ejemplo de un Data Pipeline sencillo
Te mostramos un ejemplo muy sencillo de un Data Pipeline:
Fuente: puede ser una base de datos MySQL, o noSQL como MongoDB o diferentes aplicaciones web.
Destino: podría ser una data warehouse o data lake dentro de una plataforma Cloud como podría ser AWS.
En un data pipeline, generalmente, pero no siempre, hay una fase de transformación de datos. Esto tiene sentido ya que en la mayoría de los casos los datos se almacenan en bases de datos estructuradas o en otras palabras, en tablas con columnas y filas.

Los datos son como el agua
La mayoría de nosotros tenemos la suerte de abrir el grifo cuando queremos y sale agua limpia.
¿Pero has pensado cómo llega el agua hasta tu casa?
El agua empieza en lagos, en océanos y incluso en ríos, pero la mayoría de nosotros probablemente no bebería directamente de estas fuentes, por eso tenemos que tratar y transformar esta agua en algo que es seguro para nuestro uso y lo hacemos tratando esa agua.

Esa agua se transporta en tuberías, que en inglés son “pipelines”, de ahí el nombre de data pipelines, ya que cuando hablamos de datos también debemos transportar, como agua de una fuente a un destino.
Si pensamos en cómo el agua se transporta de una fuente a un destino por tuberías, podemos usar esta analogía para los datos y los data pipelines dentro de las organizaciones que funcionan de una forma similar.
Los datos en las organizaciones comienzan en lagos de datos o data lakes, en diferentes bases de datos que forman parte de diferentes aplicaciones empresariales.
Tenemos flujos de datos en tiempo real o streaming, por ejemplo datos de sensores. Esto podría ser nuestro río.

Al igual que nuestras fuentes de agua, nuestros datos no suelen estar limpios, están contaminados y deben ser limpiados y transformados antes de ser útiles para ayudarnos a tomar decisiones de negocio.
Procesos dentro de un Data Pipeline
Cuando hablamos de data pipelines tenemos diferentes procesos que podemos usar para ayudarnos a manejar la tarea de transformar y limpiar estos datos. Podemos usar procesos como ETL, podemos utilizar la Replicación de Datos y también podemos utilizar la Virtualización de Datos.
ETL
Uno de los procesos más comunes dentro de los data pipelines es ETL (Extract Transform y Load) que significa extraer, transformar y cargar, en español. Es exactamente lo que suena, extraemos los datos de donde están, los transformamos, limpiando los datos que no coinciden, valores faltantes, quitando de datos duplicados, asegurándose de tener columnas correctas y cargándolos a un destino final como podría ser un almacén de datos de una empresa.
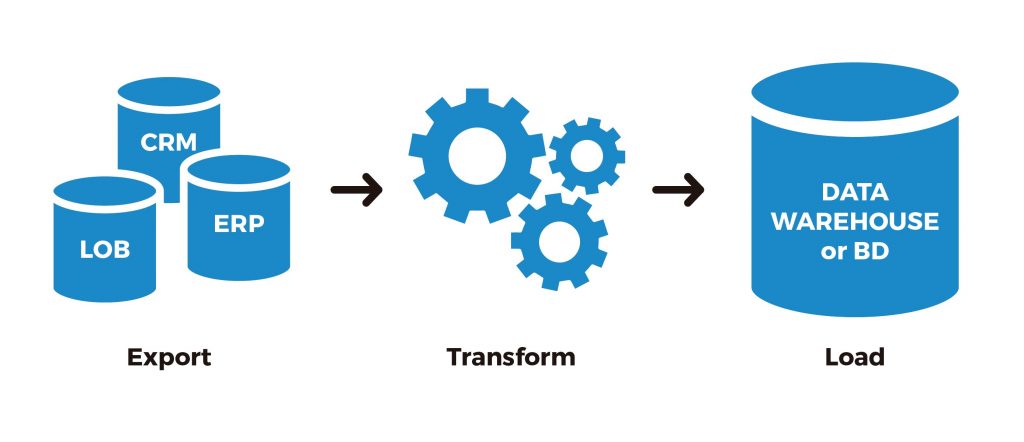
La mayoría de las veces usamos algo llamado “Batch Processing”, o procesamiento por lotes que significa que en un horario determinado cargamos los datos en nuestra herramienta ETL y luego los cargamos donde sea necesario. También podríamos tener datos en streaming o flujos de datos en tiempo real, continuamente extrayendo los datos, transformándolos y cargándolos en el destino.
Replicación de datos
Otra proceso que podríamos usar es la replicación de datos.
Esto implica una continua replicación y copiado de datos de una fuente a otro destino antes de ser cargados o utilizados por nuestro destino.
Una de las razones por las que podríamos utilizar la replicación de datos es por necesidad de alto rendimiento o para tener una copia de seguridad o backup para recuperación de desastres.
Virtualización de datos
El último proceso es la virtualización de datos. Todos los métodos descritos hasta ahora requieren que copies datos desde donde se encuentran y moverlos a un destino. ¿Pero qué pasa si queremos probar un nuevo caso de uso y no queremos crear una data pipeline permanente?
En ese caso podemos utilizar una tecnología llamada virtualización de datos para simplemente virtualizar el acceso a nuestras fuentes de datos y sólo consultarlos en tiempo real cuando los necesitamos, sin copiarlos. Una vez que estemos contentos con el resultado de nuestro caso de uso de prueba podemos volver y construir estos data pipelines. La tecnología de virtualización de datos nos permite acceder a todas estas fuentes de datos sin tener que construir data pipelines permanentes.
Una vez hecho el data pipeline y con los datos transformados y actualizados en nuestro destino ya pueden ser utilizados por nuestras aplicaciones de BI, nuestros modelos de machine learning y por cualquier otro departamento que necesite acceder a ellos para tomar decisiones de negocio.
¿Qué herramientas podemos utilizar para crear Data Pipelines?

Hay varias herramientas disponibles para construir data pipelines, algunas de las más populares son:
- Apache NiFi: es una herramienta open-source que permite la creación de flujos de datos automatizados y escalables.
- Apache Kafka: es un sistema de mensajería distribuido que se utiliza para construir data pipelines de alta velocidad y escalabilidad.
- Apache Storm: es un sistema de procesamiento en tiempo real open-source para data pipelines.
- Apache Flink: es un motor de procesamiento de datos de código abierto para procesar grandes volúmenes de datos en tiempo real.
- Apache Beam: es una biblioteca open-source para la construcción de data pipelines que permite la ejecución en múltiples sistemas, incluyendo Apache Flink, Apache Spark, y Google Cloud Dataflow.
- AWS Glue: es un servicio de extracción, transformación y carga (ETL) en la nube de Amazon Web Services.
- Azure Data Factory: es un servicio de Microsoft Azure para crear, programar y administrar flujos de trabajo de integración de datos en la nube.
- Google Cloud Dataflow: es un servicio de Google Cloud para crear pipelines de procesamiento de datos escalables y de alto rendimiento.
- Apache Airflow: es una plataforma open-source para programar, ejecutar y monitorear flujos de trabajo.
- Talend: es una herramienta de código abierto para la integración de datos y la automatización de procesos de negocio.
¿Se pueden crear data pipelines con SQL?
Sí, es posible crear data pipelines utilizando SQL (Structured Query Language). SQL es un lenguaje de programación estandarizado que se utiliza para interactuar con bases de datos relacionales. Algunas de las tareas comunes en data pipelines, como la extracción de datos de una fuente y su transformación, pueden ser realizadas utilizando consultas SQL.
Por ejemplo, se pueden utilizar consultas SQL para extraer datos de una tabla o vista en una base de datos y luego utilizar las funciones de SQL para transformar los datos en un formato adecuado para su carga en otra tabla o sistema. Algunas herramientas de data pipelines, como Talend, ofrecen una interfaz gráfica de usuario para crear flujos de trabajo de ETL que utilizan SQL. También existen algunas herramientas como Apache Nifi y Apache Airflow que permiten crear data pipelines utilizando scripts SQL.
¿Quieres aprender más y ser un experto en datos?
Si quieres convertirte en todo un experto en datos en Datademia también ofrecemos un MDA, Máster en Datos y Analitica donde aprenderás todo lo necesario para convertirte en un experto en datos y encontrar un trabajo en este mundo que no para de crecer.

Visita Datademia para inscribirte en un Máster en Datos y Analítica y conseguir tu certificado.
¡Nos vemos en clase!
Ve el artículo en formato de video
Fundador de Datademia y formador especializado en análisis de datos, ciencia de datos, ingeniería de datos y negocios.
Ayudo a profesionales a adquirir habilidades prácticas a través de formaciones online en Datademia para impulsar sus carreras. Conecta conmigo en LinkedIn.


