En este artículo vamos a hablar de cuatro datasets que puedes utilizar para empezar a aprender ciencia de datos.
Te lo contamos en este video o puedes seguir leyendo:
1. Dataset Iris
El primero y más conocido es el dataset de Iris. Este conocido dataset es utilizado en muchos proyectos de machine learning, nosotros en Datademia también lo utilizamos.

El dataset consiste de datos de un conjunto de flores Iris, de tres tipos; Setosa, Versicolour y Virginica con los datos de la longitud y ancho de sus pétalos y su sépalos.
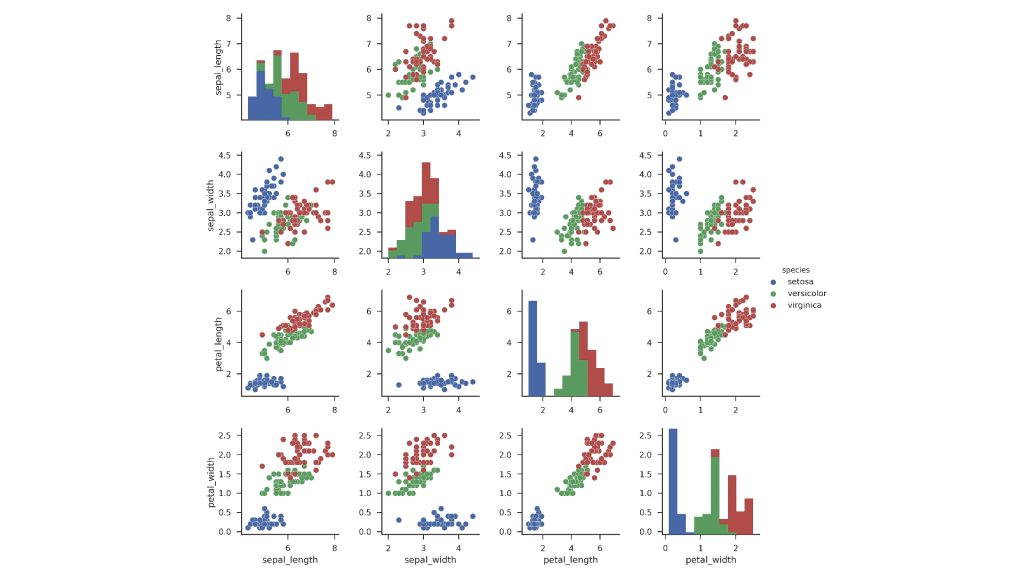
Es un dataset muy utilizado para aprender sobre visualización de datos, análisis exploratorio de los datos y modelos de machine learning básicos.
2. Precios de casas
El segundo dataset que deberías conocer es el del precio de las casas o (houses prices).

Este dataset consiste de casas residenciales en Estados Unidos, con 79 variables diferentes que se pueden utilizar para predecir el precio de la casas.
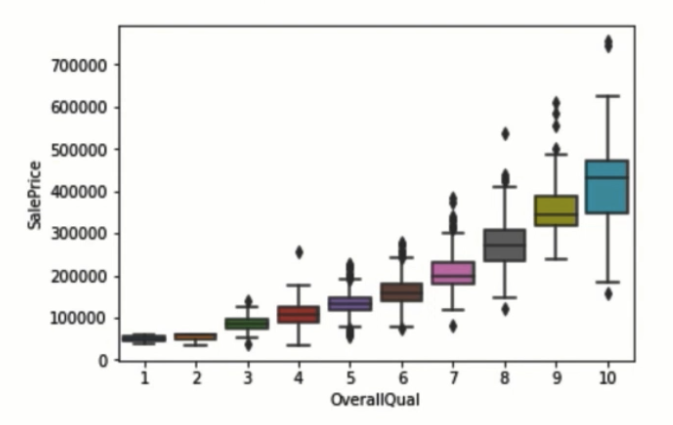
Es un dataset muy interesante y en Datademia también lo utilizamos en nuestros cursos.
3. Titanic
El dataset del titanic es mítico y es uno de los primeros datasets que se utiliza para aprender sobre la regresión logística, como predecir un resultado binario (los que sobreviven o no).

Este dataset consiste de datos de los sobrevivientes del titanic, si sobrevivieron o no y 10 variables asociadas que se pueden utilizar para predecir si alguien sobrevivió o no al famoso accidente del titanic.
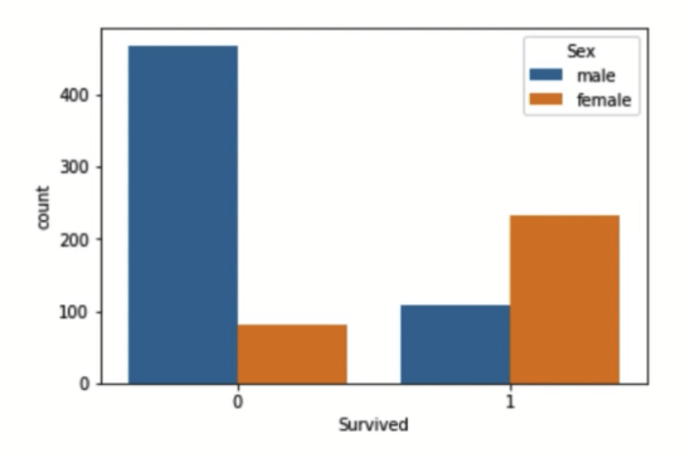
4. MNIST dataset
El dataset de MNIST o a veces llamado dígitos, consiste en un dataset de imágenes de números escritos a mano.

Este dataset es muy útil para aprender métodos de clasificación o de visión por ordenador.
¿Quieres aprender ciencia de datos?
En el Data Scientist Bootcamp de Datademia, aprenderás ciencia de datos con Python y R y saldrás listo para convertirte en un científico de datos. Te invito a visitar nuestra web para aprender más.
Si quieres profundizar aún más, ofrecemos un MDA – Máster en Datos y Analítica donde te podrás convertir en un experto en datos.

Preguntas Frecuentes (FAQ)
¿Por qué son importantes los datasets para aprender ciencia de datos?
Los datasets son cruciales en el aprendizaje de ciencia de datos porque proporcionan una base realista para practicar técnicas de análisis de datos, visualización, y modelado predictivo. Trabajar con datasets permite a los principiantes familiarizarse con los desafíos y preguntas que los científicos de datos enfrentan cotidianamente.
¿Qué es el dataset Iris y qué puedo aprender de él?
El dataset Iris contiene datos sobre las dimensiones de los pétalos y sépalos de tres especies de la flor Iris. Es ideal para aprender sobre visualización de datos, análisis exploratorio básico, y la implementación de modelos de clasificación simples en machine learning.
¿Cómo el dataset de precios de casas puede ayudar a un principiante en ciencia de datos?
Con 79 variables explicativas, el dataset de precios de casas ofrece una oportunidad excelente para practicar la limpieza de datos, el análisis exploratorio avanzado, y la construcción de modelos predictivos para estimar el valor de propiedades residenciales en Estados Unidos.
¿Qué enseñanzas ofrece el dataset del Titanic para los aspirantes a científicos de datos?
El dataset del Titanic es perfecto para aprender sobre regresión logística y otros métodos de clasificación para predecir categorías binarias, como la supervivencia de los pasajeros. También es una buena introducción al tratamiento de datos categóricos y faltantes.
¿Por qué el dataset MNIST es relevante para los interesados en visión por computadora?
MNIST, compuesto por imágenes de dígitos escritos a mano, es fundamental para quienes están interesados en la visión por computadora y la clasificación de imágenes. Permite practicar con algoritmos de clasificación y técnicas de procesamiento de imágenes.
¿Qué proyectos puedo realizar con estos datasets para mejorar mis habilidades en ciencia de datos?
Puedes iniciar con proyectos de visualización y análisis exploratorio, seguir con la implementación de modelos de clasificación y regresión, y finalmente, adentrarte en proyectos más complejos de visión por computadora con el dataset MNIST. Estos proyectos fortalecerán tu comprensión de las técnicas estadísticas y de machine learning.
¿Dónde puedo encontrar estos datasets y recursos adicionales para aprender ciencia de datos?
Estos datasets están disponibles en repositorios públicos como Kaggle, UCI Machine Learning Repository, y directamente en bibliotecas de programación como Scikit-learn. Datademia ofrece cursos y bootcamps donde estos datasets son utilizados para enseñar ciencia de datos aplicada, brindando a los estudiantes una base sólida en el análisis de datos y machine learning.
Fundador de Datademia y formador especializado en análisis de datos, ciencia de datos, ingeniería de datos y negocios.
Ayudo a profesionales a adquirir habilidades prácticas a través de formaciones online en Datademia para impulsar sus carreras. Conecta conmigo en LinkedIn.


