Machine Bias es la inclusión de los prejuicios y sesgos de los datos que se usan para crear algoritmos de machine learning.

El término Machine Bias, quizá no te suene, pero está por todas partes.
Lo que sí te sonará es el término Machine Learning, o aprendizaje automático que es una disciplina del campo de la inteligencia artificial que, a través de algoritmos, dota a los ordenadores de la capacidad de identificar patrones en datos masivos y elaborar predicciones a partir de esos datos.
Evolución y ejemplos del Machine Bias
Durante los últimos años, con el creciente uso de este tipo de tecnologías, se han ido descubriendo múltiples sesgos en los resultados de los algoritmos que nos deberían hacer pensar.
Si bien el aprendizaje automático ofrece una fuente de información muy valiosa y nos dota de herramientas de gran utilidad para comprender el mundo que nos rodea, los sesgos descubiertos podrían resultar contraproducentes para el interés general o beneficiar a algunos en detrimento de otros.
Hay muchos ejemplos de ello. Un ejemplo lo encontramos en 2015, cuando un desarrollador de software advirtió que el servicio de reconocimiento facial de Google había etiquetado las fotos de una pareja negra como “gorilas”. Google se disculpó y declaró que estaba trabajando en soluciones a largo plazo para solventar este problema.
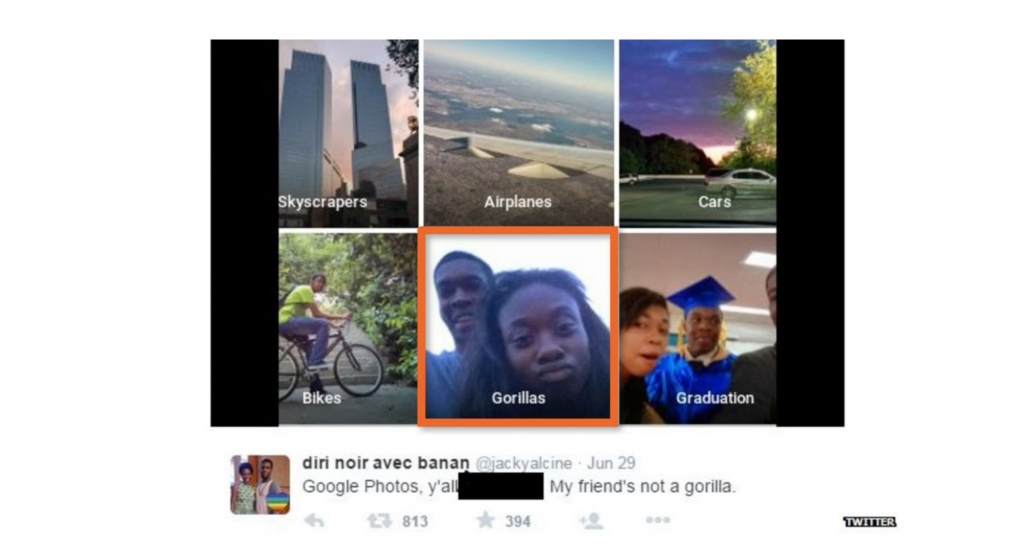
Más de dos años después, esos arreglos fueron borrar los términos relativos a gorilas y algunos otros primates del léxico del servicio, una solución poco satisfactoria para muchos, que ponía de manifiesto las dificultades a las que se enfrentan las compañías de tecnología cuando buscan ofrecer servicios de calidad fundamentados en aprendizaje automático.
Otro ejemplo en 2016 fue cuando se descubrió que algunos de los algoritmos de LinkedIn tenían un sesgo de género que, por ejemplo, recomendaba a más hombres para un puesto de trabajo que mujeres simplemente porque el algoritmo encontró que los hombres eran más agresivos en su búsqueda.
Otro ejemplo más reciente es el nuevo modelo DALL-E 2 de OpenAI, que convierte textos a imágenes de una manera muy realista. Estos modelos están llenos de sesgos, y los creadores lo saben. Los casos que verás a continuación vienen de la documentación de DALL-E 2.
Cuando le pedimos al modelo que genere un ‘builder’, lo que sería un albañil, vemos que nos genera personas blancas de género masculino:

Cuando le pedimos que genere una imagen de un auxiliar de vuelo, nos genera imágenes de chicas jóvenes de origen asiático:

Cuando le pedimos que nos genere imágenes de una boda, nos genera imágenes de una boda heterosexual con vestidos blancos y flores, lo tradicional.

Cuando le pedimos que nos genere imágenes de un abogado (lawyer), nos genera imágenes de hombres blancos mayores, aunque en inglés el termino ‘lawyer’, no significa que sea ni mujer ni hombre.

Para enfermeras, el modelo automáticamente nos crea imágenes de mujeres, aunque en inglés el termino ‘nurse’, no significa que sea ni mujer ni hombre.

Como veis, el modelo ha aprendido a incluir muchos sesgos en sus resultados, provenientes de los datos con los que trabaja.
Nadie duda del gran potencial que tienen estas nuevas tecnologías, que están empezando a hacer cosas que nunca imaginamos posibles. Pero aún nos falta experiencia en el correcto desarrollo de estos algoritmos sin que tengan estos sesgos.
Un modelo es tan bueno como los datos de los que aprende, y entrenar un modelo con datos sesgados en una determinada dirección puede afectar seriamente a los resultados de estos modelos.
¿Cómo funcionan los modelos de Machine Learning?
Hay dos tipos principales de modelos; supervisados y no supervisados. Los principales pasos para el uso de un modelo de Machine Learning son el procesamiento de los datos, el ajuste del modelo, la realización de predicciones y la evaluación de los resultados.
Llamamos aprendizaje supervisado cuando se entrena un algoritmo con datos ya conocidos o etiquetados. Cuanto más datos haya, más aprenderá el algoritmo y una vez concluido el entrenamiento, como se le dan nuevos datos, sin las etiquetas, el algoritmo podrá predecir mejor los resultados.

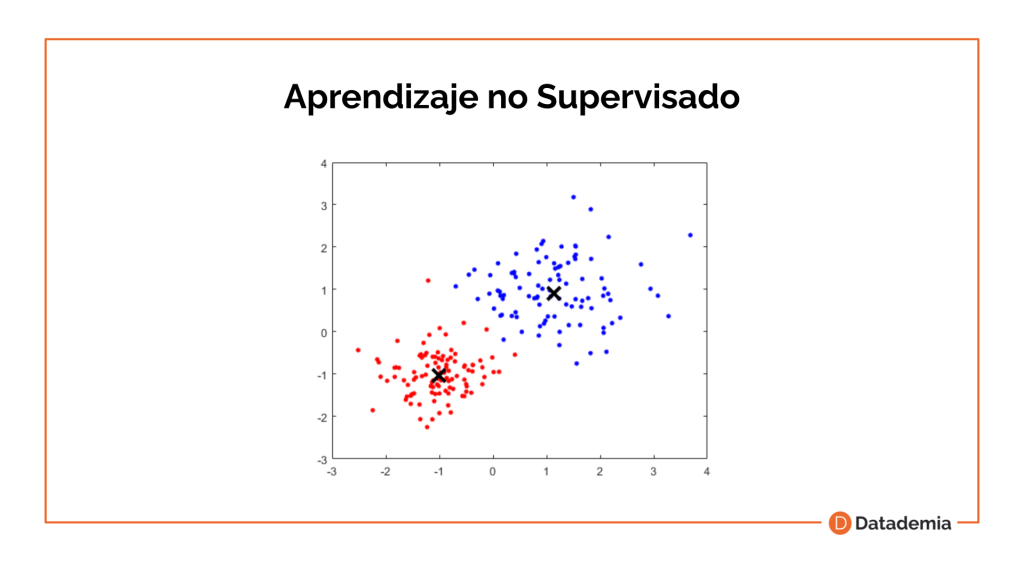
Por otro lado, tenemos al aprendizaje no supervisado, donde sólo se proporcionan los datos de entrada al modelo. El algoritmo es entrenado usando un conjunto de datos que no tienen ninguna etiqueta, nunca se le dice al algoritmo lo que representan los datos. La intención es que el algoritmo pueda descubrir por sí solo patrones que ayuden a entender el conjunto de datos.
¿Qué tipos de sesgos existen en el Machine Learning?
Lo primero que debemos hacer es entender lo que es el Machine Bias y cómo algunos sesgos están representados en los datos que recogemos y en los métodos utilizados para muestrear, agregar, filtrar y mejorar esos datos.
Vamos a hablar de algunos:
- Sesgo de muestreo: Esto ocurre cuando recogemos datos donde hacemos un sobremuestreo de un grupo de datos más que de otro dandole más peso en nuestro modelo. El muestreo debe ser siempre de forma aleatoria.
- Sesgo de medición: El sesgo de medición se da cuando no se mide y se registra con precisión los datos que se han seleccionado. Por ejemplo, si se utiliza el salario como medida, puede haber diferencias salariales que incluyen primas u otros incentivos, o diferencias regionales en los datos.
- Sesgo de exclusión: Al igual que el sesgo de muestreo, el sesgo de exclusión surge de los datos que se eliminan inadecuadamente de la fuente de datos. Cuando se tienen petabytes o más de datos, es tentador seleccionar una pequeña muestra para utilizarla en el entrenamiento, pero al hacerlo se pueden excluir inadvertidamente ciertos datos, lo que da lugar a un conjunto de datos sesgado. El sesgo de exclusión también puede ocurrir debido a la eliminación de duplicados de datos cuando los elementos de datos son realmente distintos.
- Sesgo del experimentador: A veces, el propio acto de registrar los datos puede estar sesgado. Cuando se registran los datos, a veces solo se registran ciertas instancias de datos, y omitimos otras. Por ejemplo, puedes estar creando un modelo de aprendizaje automático basado en los datos de los sensores, pero sólo coges muestras cada pocos segundos, omitiendo elementos de datos clave.
- Sesgo de prejuicio: Cuando utilizamos datos históricos para entrenar modelos, especialmente en áreas que han estado previamente plagadas de prejuicios, hay que tener cuidado para asegurarse de que los nuevos modelos no incorporan ese sesgo.
- Sesgo de confirmación: El sesgo de confirmación es el deseo de seleccionar sólo la información que apoya o confirma algo que ya se sabe, en lugar de los datos que podrían sugerir. El resultado son datos contaminados porque han sido seleccionados de forma sesgada o porque se descarta la información que no confirma la noción preconcebida.
- Efecto bandwagon: El efecto bandwagon es una forma de sesgo que se produce cuando hay una tendencia en los datos. A medida que la tendencia crece, los datos que apoyan esa tendencia aumentan y los científicos de datos corren el riesgo de sobre representar la idea en los datos que recogen.
¿Cómo podemos eliminar el Machine Bias?
Con toda esta información, os seguiréis preguntando cómo podemos eliminar el Machine Bias.
Una vez que hemos entendido qué sesgos ocurren y porqué, vamos con recomendaciones para reducir el impacto de los mismos:
- Identifica las posibles fuentes del sesgo: Examina los datos y entiende cómo los diferentes sesgos podrían afectar. ¿Te has asegurado de que no hay ningún sesgo derivado de captura u observación de datos? ¿Te has asegurado de no utilizar un conjunto de datos históricos contaminados por prejuicios? Hacernos estas preguntas puede ayudar a identificar lo que sucede.
- Establecer directrices y normas para eliminar el sesgo y los procedimientos: Hay empresas que ya están estableciendo procedimientos para identificar, comunicar y mitigar los posibles sesgos que pueden aparecer. Al establecer estas normas y comunicarlas de manera abierta y transparente, las organizaciones pueden dar el paso correcto para abordar los problemas de sesgo de los modelos de aprendizaje automático.
- Identificar datos representativos precisos: Antes de recopilar y agregar datos para el entrenamiento del modelo de aprendizaje automático, puedes tratar de entender cómo debe ser un conjunto de datos representativo.
- Documentar y compartir cómo se seleccionan y limpian los datos: Documentar los métodos de selección y limpieza de datos y permitir que otros examinan si los modelos presentan alguna forma de de sesgo puede ayudar a analizar las causas de las fuentes de sesgo para eliminarlas en futuras iteraciones del modelo.
- Evaluar el modelo en función del rendimiento y seleccionar el menos sesgado: Los modelos de aprendizaje automático suelen evaluarse antes de ponerlos en funcionamiento. La mayoría de las veces, estos pasos de evaluación se centran en aspectos de exactitud y precisión del modelo. Podríamos añadir medidas de detección de sesgos en los pasos de evaluación de modelos.
- Supervisar y revisar los modelos en funcionamiento: Existe una diferencia entre el rendimiento del modelo de aprendizaje automático en el entrenamiento y su rendimiento en el mundo real. Proporcionar métodos para supervisar y revisar continuamente los modelos mientras funcionan puede ser una manera de mejorar los procesos.
Conclusión
A medida que la inteligencia artificial siga formando parte de nuestras vidas cada día en una mayor manera, los riesgos de sesgo aumentan.
En un futuro no muy lejano, las empresas, los investigadores y los desarrolladores tendrán la responsabilidad de minimizar los sesgos en los sistemas de IA.
Gran parte de esto se reduce a garantizar que los conjuntos de datos sean representativos y que la interpretación de los conjuntos de datos se entienda correctamente.
¿Quieres ver este artículo en formato vídeo?
En este vídeo Sebastian nos habla del Machine Bias en nuestro canal de Youtube:
Fundador de Datademia y formador especializado en análisis de datos, ciencia de datos, ingeniería de datos y negocios.
Ayudo a profesionales a adquirir habilidades prácticas a través de formaciones online en Datademia para impulsar sus carreras. Conecta conmigo en LinkedIn.



1 comentario en “Machine Bias: Sesgos Inconscientes en el Machine Learning”
muy interesante algo totalmente nuevo para mí que lo había escuchado de personas que hacen o corren en forex y desconocía por completo que son temas estadísticos de evaluación de los sesgos en data