Web Scraping refiere al proceso de recolectar datos desde la web, ya sea de forma manual o automática. Específicamente la palabra “Scraping” nos da una intuición de lo que implica esta técnica, ya que traducida al español significa raspar, reunir, arañar.
Como se ve a continuación, Web Scraping no es la única técnica de extracción de información, pero presenta algunas ventajas (y desventajas) por sobre las otras, también sus usos son diferentes.
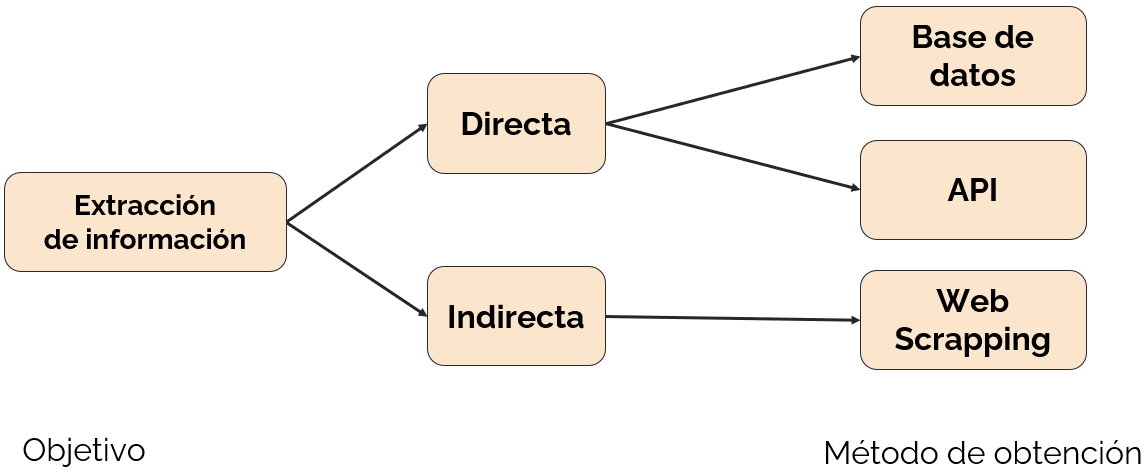
Con Web Scraping se extrae el contenido HTML de páginas web para filtrar la información requerida y almacenarla, de forma comparable al proceso automático de copiado y pegado. En el caso de la búsqueda de imágenes, el proceso se denomina acertadamente Image Scraping.
¿Dónde se utiliza Web Scraping?
Dentro de sus usos legítimos se encuentran los motores de búsqueda web tales como Google, los cuales rastrean los diferentes sitios web, para analizar su contenido y almacenarlo. De esta forma, y utilizando el algoritmo “Page Rank” (con “Random Surfer”) recomiendan dichos sitios web a sus usuarios.

Otros ejemplos de grandes compañías que utilizando Web Scraping son aquellos sitios que comparan precios de, por ejemplo, hoteles, alquileres de vehículos o vuelos. O bien compañías que necesiten recabar información de parte de sus competidores, o de sus usuarios mediante, por ejemplo, menciones en redes sociales.

¿Cómo funciona Web Scraping?
Una vez que se identifica qué información se requiere, y de que sitio web se puede extraer, se procede a la construcción de un bot o robot, llamado Web Scraper, el cual extraerá datos específicos de un sitio web.
Aclaración: Para que un robot se considere legítimo y no malicioso, debe respetar, entre otras cuestiones, las reglas de escapeo definidas por el sitio web al cual se desee escrapear en el archivo robots.txt.

Para ello, primero se extrae todo el contenido de un sitio web de forma indiscriminada, desde la estructura hasta el contenido. Este primer paso se conoce como Web Crawling, y aunque en diversas fuentes se mencione como algo ajeno a Web Scraping, en verdad es parte su amplio proceso. Luego, el contenido deseado se identifica y extrae.
Finalmente, se encuentra la etapa de limpieza y formateo de los datos. En este paso, la información extraída es post-procesada como en el caso de texto y almacenada en archivos de datos estructurados, tales como JSON o XML, mediante analizadores sintácticos (Parsers). O bien, en objectos de Python como Numpy arrays, Pandas DataFrames, diccionarios, entre otros.
¿Cómo funciona una solicitud web?
Al ingresar una dirección en un navegador web, estaremos enviando una solicitud HTTP a un servidor, y este responderá con un contenido HTML, que nuestro navegador web renderizará. El usuario final entonces, sólo verá el contenido HTML renderizado por su propio navegador web.
El problema es que cuando introducimos una dirección web, por ejemplo “https://datademia.es/”, en un navegador, no nos podremos comunicar con el servidor que hostea el sitio web de Datademia, ya que necesitamos su dirección IP pública para ello. Es por ello que el servidor de registro de dominios actúa de intermediario entre nuestro navegador y el servidor.

¿Por qué utilizar Python para Web Scraping?
Python 3 es el mejor lenguaje de programación para realizar tareas de web scraping debido a su velocidad y facilidad de uso. Además de los populares frameworks que presenta para realizar tareas relacionadas a Web Scraping tales como Scrapy, Selenium, y librerías tales como Beautiful Soup, Requests, lxml. Sumado a esto, el manejo de archivos, procesamiento de datos y la capacidad de integrar una simple aplicación de Web Scraping a un proyecto de mayor escala en Python no son tareas difíciles de realizar.
¿Donde aprender Web Scraping?
Estas de suerte ya que en Datademia ofrecemos un curso de Web Scraping con Python.

Apúntate hoy mismo para empezar tu camino con el Web Scraping.
Preguntas Frecuentes (FAQ)
¿Qué es Web Scraping y cómo se diferencia de otras técnicas de extracción de datos?
Web Scraping es una técnica que permite recolectar datos de páginas web de forma automatizada, extrayendo el contenido HTML para filtrar y almacenar la información deseada. Se diferencia de otras técnicas de extracción de datos por su enfoque en el contenido web y su capacidad para recopilar datos específicos de manera eficiente.
¿Cuáles son los principales usos legítimos del Web Scraping?
Entre los usos legítimos del Web Scraping se incluyen la indexación de contenido por motores de búsqueda, la comparación de precios en sitios de e-commerce, la recopilación de datos de mercado y análisis competitivo, así como el monitoreo de menciones en redes sociales.
¿Cómo se realiza el Web Scraping de forma ética y legal?
Realizar Web Scraping de forma ética y legal implica respetar las políticas de uso de los sitios web, específicamente el archivo
robots.txt, que indica las directrices sobre qué partes del sitio pueden ser raspadas. También es importante no sobrecargar los servidores del sitio web con solicitudes y utilizar los datos de manera responsable.¿Qué tecnologías y lenguajes de programación se utilizan comúnmente para Web Scraping?
Python es el lenguaje de programación más popular para Web Scraping debido a su simplicidad y la disponibilidad de bibliotecas especializadas como Scrapy, Selenium y Beautiful Soup. Estas herramientas facilitan la extracción y el manejo de los datos recopilados.
¿Cuáles son los primeros pasos para empezar un proyecto de Web Scraping?
Los primeros pasos incluyen definir claramente el objetivo del scraping, identificar las fuentes de datos web, familiarizarse con la estructura HTML de las páginas de interés, y elegir las herramientas y bibliotecas adecuadas para el proyecto. Es crucial también considerar las implicaciones legales y éticas del scraping.
¿Dónde puedo aprender más sobre Web Scraping y poner en práctica esta técnica?
Datademia ofrece un curso específico de Web Scraping con Python, diseñado para enseñarte las habilidades necesarias para recopilar datos de la web de manera efectiva. Este curso te proporcionará una base sólida, desde el manejo de bibliotecas hasta la implementación de proyectos reales de scraping.
¿Qué desafíos se pueden encontrar al realizar Web Scraping y cómo superarlos?
Los desafíos incluyen lidiar con sitios web dinámicos que utilizan JavaScript, manejar la paginación y el scrolling infinito, evitar ser bloqueado por mecanismos anti-scraping, y mantener el scraper actualizado ante cambios en la estructura del sitio web. Superar estos desafíos requiere una combinación de técnicas avanzadas de scraping, uso de proxies, y familiarización con tecnologías web modernas.
Fundador de Datademia y formador especializado en análisis de datos, ciencia de datos, ingeniería de datos y negocios.
Ayudo a profesionales a adquirir habilidades prácticas a través de formaciones online en Datademia para impulsar sus carreras. Conecta conmigo en LinkedIn.


